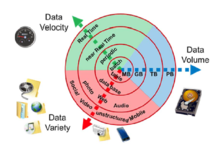
There are additionally other preferred collections, such as Demands as well as Gorgeous Soup, which might give a better programmer experience when composing HTTP demands and also handling HTML documents. If you wan to read more, you can inspect this overview concerning the very best Python HTTP customer. In method, internet crawlers just see a part of web pages depending on the crawler budget, which can be an optimal variety of web pages per domain, deepness or execution time. Collecting info from the internet can be like drinking from a fire hose. There's a lot of things available, and also it's not constantly clear what you need or just how you require it.
- The new function build_absolute_url converts relative Links to absolute URLs.
- Prior to finishing this post I think it would be rewarding to actually see what's fascinating about this data we simply recovered.
- Before we begin constructing the spider utilizing workers, allow's discuss some basics.
- Selenium is largely a browser automation device developed for internet screening, which is also located in off-label use as an internet scraper.
This usage situation is extremely questionable as well as commonly requires approval to collect this type of data. To understand which of the two is suitable for your company needs, one must seek qualified advice to see to it that secure as well as lawful data removal is made with utmost care and precision. It is essential for your company's success that you use the best online scratching services/crawling tools offered.
Make Use Of User Agents
An internet crawler is a web crawler or a program that assists in web indexing. It browses through the web in a methodical way as well as searches for elements such as the keyword phrases in each page, the sort of material it contains, the web links, and so on. Hereafter, it collects all this incorporated info and also returns it to the online search engine. This is the most basic way of clarifying the method of internet crawling.
What is the difference between creeping and surfing?
A crawler is a computer system program that scans documents online immediately. Spiders are primarily set to make sure that browsing is automated for repetitive actions. Internet search engine use spiders most often to search the Internet as well as create an index.
Customer representatives enable the web server you wish to scrape to recognize which web browser, running system, or tool you are making use of. You will certainly recognize your ID in the means the web browser's customer representative style you utilized in your connection requests. Nevertheless, the server will identify and also outlaw you if you make multiple requests to the server with the very same individual representative. To prevent being blocked, make use of a major web browser's user representative as well as change it regularly. Robots.txt allows or rejects accessibility to Links on an internet site to limit the crawl price. When an internet site spots an internet spider, it will blacklist IP addresses to prevent their web sites from being crawled.

Spider Catch
Proceeding with the previous instance, when you search for internet creeping vs. internet scraping, the online search engine creeps every one of the web's website, including pictures as well as video clips. Internet search engine make use of internet spiders to creep all pages by following the links installed on those web pages. Web crawlers find new links to various other Links as they crawl pages and also add these uncovered links to the crawl line up to creep following.
As a result of that, both libraries have lots of similarities, lowering the discovering contour as well as Extra resources decreasing the trouble of moving from one collection to another. Internet browsers are a method for individuals to accessibility and communicate with the info available on the internet. However, a human is not always a need for this interaction to occur. Web browser automation tools can resemble human activities as well as automate an internet internet browser to execute repeated and also error-prone tasks. The goal of the task is to make HTTP requests simpler as well as a lot more human-friendly, thus the title "Requests, HTTP for humans." Got Scraping is a modern plan expansion of the Got HTTP client.
You will certainly learn to use CSS selectors as well as XPath expressions to extract purposeful data from HTML records. IMDb reroutes courses under/ whitelist-offsite and also/ whitelist to exterior domain names. There is an open Scrapy Github problem that reveals that external Links do not get removed when OffsiteMiddleware is applied before RedirectMiddleware. To repair this problem, we can configure the web link extractor to skip Links starting with two routine expressions.
As the web crawler parses as well as brings the link, it will certainly find brand-new links embedded in the web page. To determine which is best for your demands or just how to incorporate them for your internet scratching job, you require to comprehend the distinctions between web scratching and internet crawling. Their use varies in levels, as well as you can pick from the ones available, relying on whichever matches your criteria for information need one of the most. Nonetheless, just a couple of take care of to make a name in the information sector, the factor being that the task of an efficient web crawler is not as simple one. Information scraping has come to be the utmost device for business advancement over the last decade.
On the other hand, Python could be your finest selection if you are also thinking about information API Integration Services scientific research as well as artificial intelligence. These fields greatly gain from having accessibility to large sets of information. Consequently, by grasping Python, you can get the needed information via internet scuffing, process it, and then directly use it to your project. Cheerio Scraper is a ready-made option for creeping web sites making use of simple HTTP requests.
https://maps.google.com/maps?saddr=619-2%20Carlton%20St.%2C%20Toronto%2C%20ON%20M5B%201J3%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
This tutorial reveals you how to parse HTML and also remove information from the web content using normal expressions. To limit the variety of crawled Links, we can get rid of all question strings from URLs with the url_query_cleaner function from the w3lib collection and also utilize it in process_links. If you do not locate a specific debate for your usage instance, you can make use of the criterion Web Scraping process_value of LinkExtractor or process_links of Rule. As an example, we obtained the exact same page twice, once as simple link, another time with extra inquiry string parameters.
Scientists develop 'wildDISCO' method to detect tiny cancerous tumors - Interesting Engineering
Scientists develop 'wildDISCO' method to detect tiny cancerous tumors.
Posted: Tue, 11 Jul 2023 13:39:00 GMT [source]
What is the difference in between ditching as well as crawling?
Web scuffing goals to remove the data on web pages, and internet crawling purposes to index as well as discover websites. Internet crawling entails adhering to links permanently based upon links. In contrast, internet scraping suggests composing a program computing that can stealthily accumulate information from a number of websites.